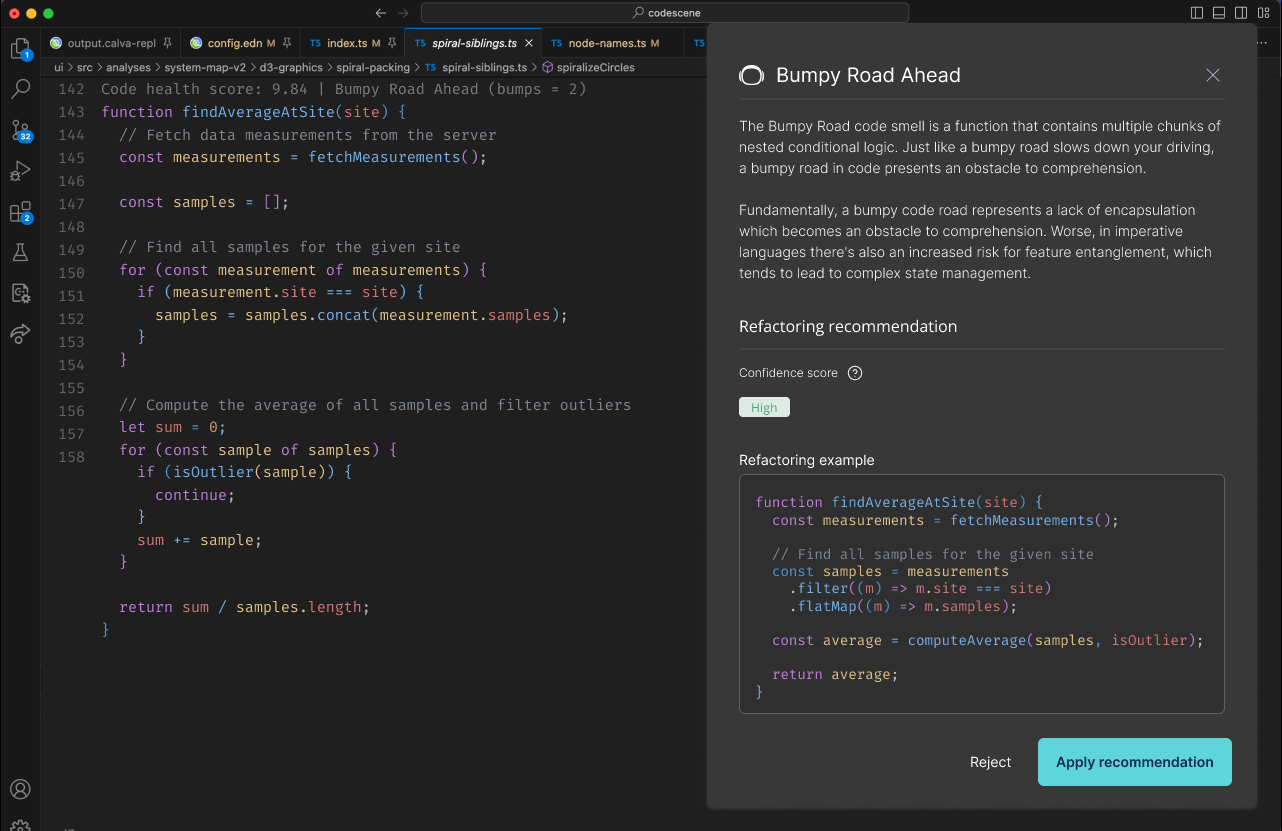
CodeScene lets you uncover and prioritize code that’s hard to maintain or parts of the code that become team productivity bottlenecks.
As such the techniques are reactive. Wouldn’t it be great if we could catch such problems much earlier, ideally before they are even delivered to our main branch?
In this blog post we explore a new feature of CodeScene that turns the analyses into a pro-active tool for early feedback. You’ll see how CodeScene offers the ability to detect maintenance problems and early warnings in your codebase by integrating the analysis results into your build pipeline and/or as robot comments in a code review tool like Gerrit.
Fight reviewer fatigue
The challenge with all preventive and corrective techniques is that they require time and discipline. Let’s take code reviews as an example. Code reviews done right are a proven defect removal technique. A code review is also an opportunity for knowledge sharing and learning. However, none of those benefits come for free.
Like all manual processes code reviews are hard to scale. As your organization grows, code reviewer fatigue becomes a real thing; There’s just so many lines of code you can review each day. Beyond that point you’re likely to slip. The result is increased lead times, bugs that pass undetected to production, and – in extreme cases – the risk for burnout.
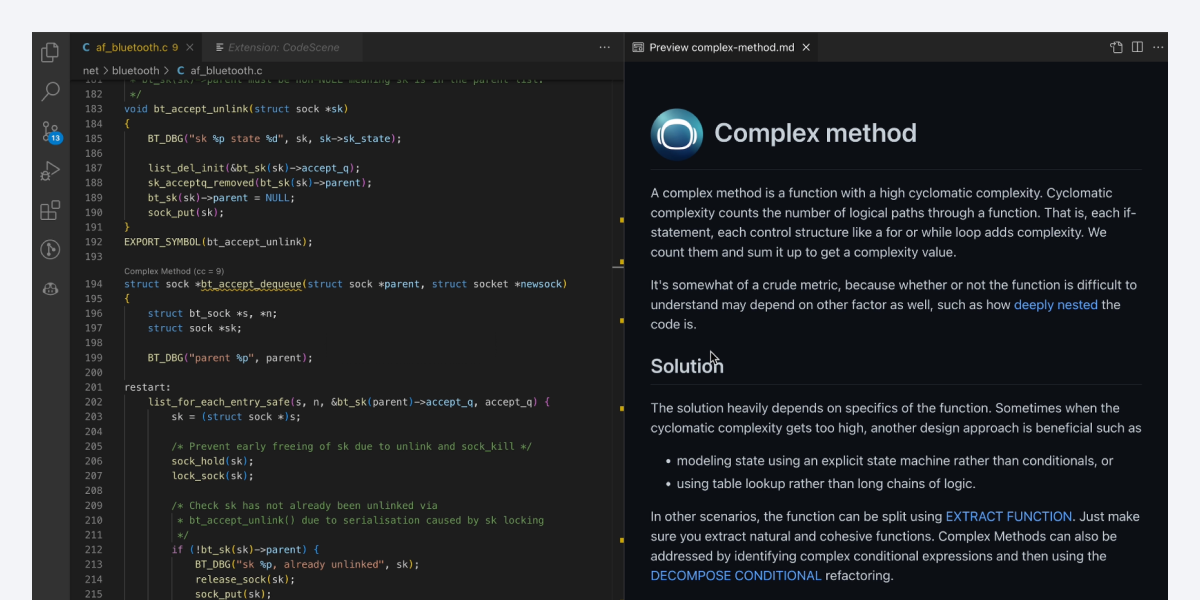
At Empear we’ve developed a system for automated risk classifications to prioritize the code we need to review. The risk classification is built into CodeScene, which exposes a REST API that lets you integrate the classification into your continuous integration pipeline. The following figure shows an example from a Jenkins build:
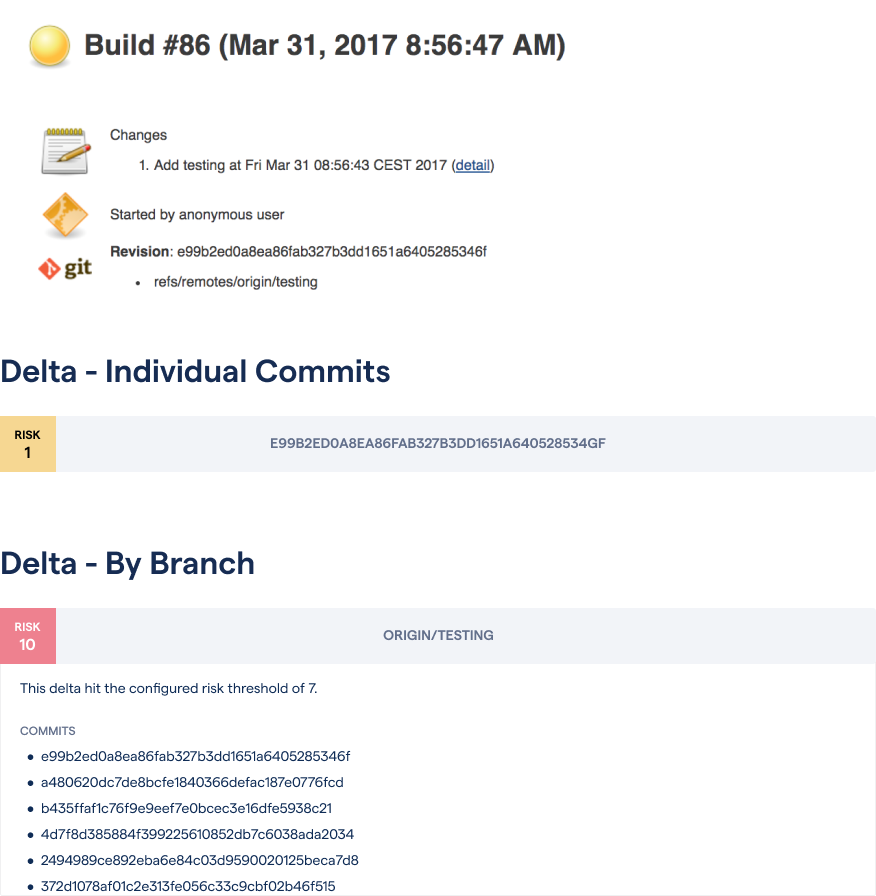
CodeScene detects high risk changes on your development branches.
The analysis is triggered by a pull request, a range of commits, or a single commit; You decide through the API. The resulting risk classification helps us developers focus our time and expertise to the areas where it’s likely to be needed the most and it does so before we even know we might have a problem. Let’s look at a specific example.
What’s a High Risk Commit?
Any risk classification algorithm has to go beyond technology and include a social dimension too; Reasoning about risk based on code alone is misleading. Let me give you an example.
Let’s say that I do a large, sweeping change to the Linux kernel. Now, pretend that Linus Torvalds would do exactly the same changes. Do our individual changes carry the same risk? Obviously not - Linus knows the code and has worked on it for almost three decades while I’ve never touched the kernel before. Clearly, Linus’s change set should be considered less risky than mine.
CodeScene resolves this by a machine learning algorithm that calculates a unique risk profile for your codebase. The risk profile is based on how the system has evolved and what a typical change looks like. That is, CodeScene looks more at how a commit impacts the system than the changed code itself. The technical metrics relate to the amount of code that is changed, the complexity of the changed code, and the diffusion of the changes (e.g. how many different sub-systems does the commit touch).
The social dimension of the risk profile relates to the experience of the programmer doing the change. The more experienced the programmer, the lower the risk. This means that two commits with identical changes may be classified differently depending on the programmers behind them. Experience mediates risk. We’ve also designed the feature as a self learning algorithm that automatically adjusts as a developer gains more experience.
Before we move on I’d like to point out that CodeScene never exposes its experience scores. The main reason is because such metrics are way too easy to misinterpret as some kind of ill-advised performance evaluation. With that covered, let’s see what’s possible once we integrate analysis information into our daily workflow.
CodeScene as an extra team member
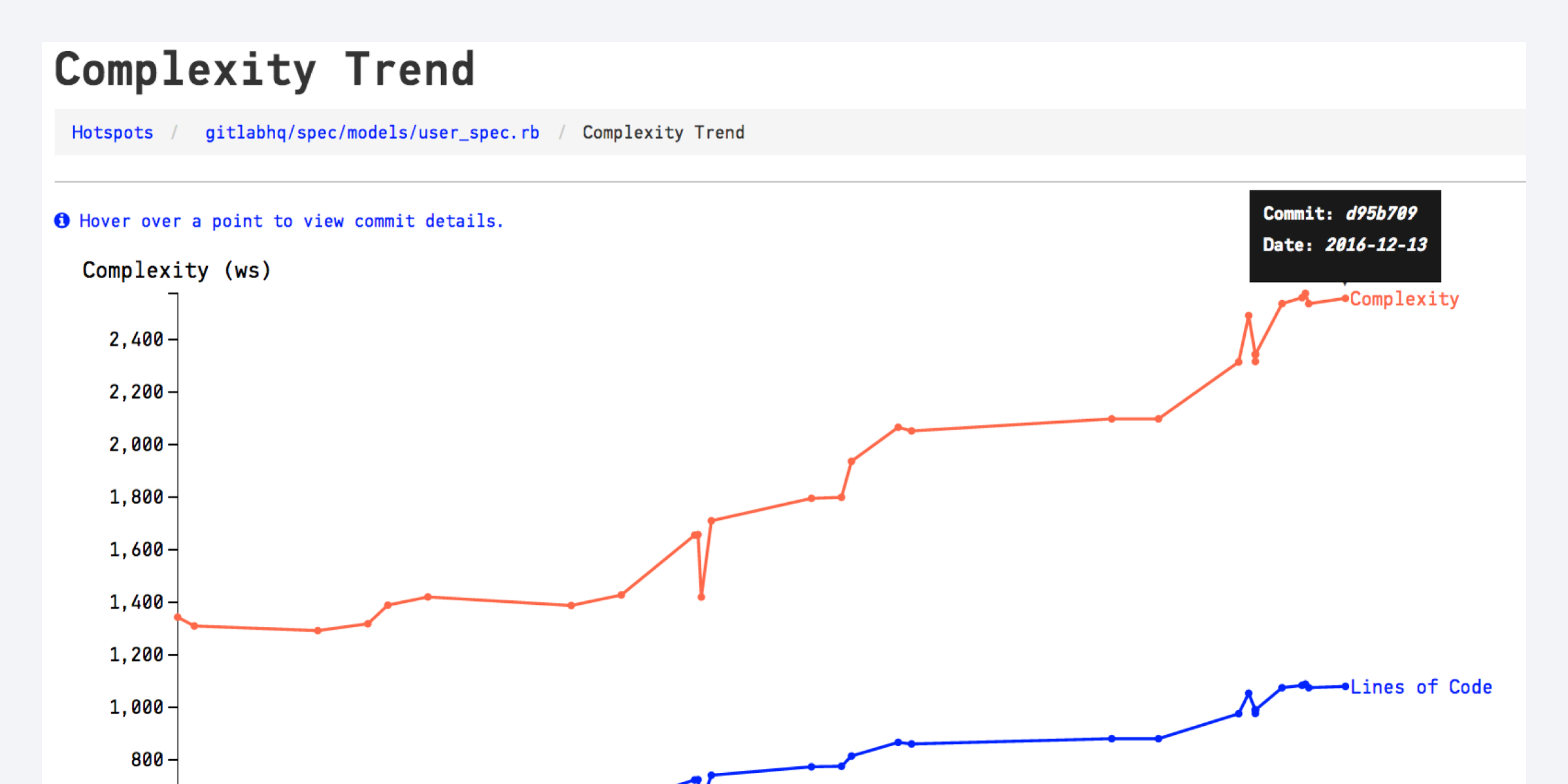
If you use CodeScene you’re familiar with its early warning system. For example, CodeScene detects complexity trends where a piece of code becomes increasingly more difficult to maintain over time:

Get automated warnings for steep complexity increases.
By integrating CodeScene in your build pipeline you get those early warnings immediately as you push a commit. This is information that you use to guide your code reviews.
In addition, CodeScene will be able to detect the absence of expected change patterns. CodeScene basically tells you that “hey, when your team members change this piece of code they also normally make a change to the file over here - did you forget to change that file?”. The following figure shows an example:
 Automated warnings for absent but expected change patterns.
Automated warnings for absent but expected change patterns.
The absent change pattern warning is based on CodeScene’s temporal coupling analysis: If a cluster of files have changed together for a long time they are intimately related. In the example above, a commit modified the file LinkTagHelper.cs. CodeScene knows that in 90% of all modifications to that file, a related class named ScriptTagHelper.cs is changed too.
The warning fires when such a temporal change pattern is broken. Please note that this may be a good sign – perhaps we just refactored some code duplication – but it may also be a sign of omission and a potential bug. As a consequence, this warning is based on a self-correcting algorithm; If you keep ignoring the warning it will go away automatically as the temporal coupling decreases below the thresholds.
Used this way, CodeScene takes on the role of an extra team member. It’s available to all teams, all the time. CodeScene never becomes bored or fatigued. It even aims to be friendly.
The main advantage of CodeScene’s continuous integration support is that it lets you react to potential problems early. But there’s a potentially large saving at the other end of the spectrum too; Instead of treating all pull requests as equals, CodeScene’s risk classification lets you prioritize your code reviews and focus your time where (and when) it’s likely to be needed the most. Code reviewer fatigue is a real thing, so let’s use our time wisely.
Explore CodeScene
The continuous integration support is available today in our on-premises version of CodeScene. We also plan to support it in codescene.io by integrating with GitHub to provide automated feedback on pull requests.